


 When discussing SEO techniques, you may come across the topic of “Duplicate Content”. Ever since Google’s Panda update was released, there has been a common misconception that duplicating content either within your own web pages or across other domains will penalize or de-index your website. While duplicate content won’t cause the King of the Internet (yes, we mean Google) to throw your site in their imaginary “sand box”, there are some things you do need to worry about. But first, let’s define what exactly duplicate content is:
When discussing SEO techniques, you may come across the topic of “Duplicate Content”. Ever since Google’s Panda update was released, there has been a common misconception that duplicating content either within your own web pages or across other domains will penalize or de-index your website. While duplicate content won’t cause the King of the Internet (yes, we mean Google) to throw your site in their imaginary “sand box”, there are some things you do need to worry about. But first, let’s define what exactly duplicate content is:
Essentially, Duplicate Content is “substantive blocks of content within or across domains that either completely match other content or are appreciably similar.” For instance:
The best way to avoid wasted pages full of duplicate content that will do your site no good at all is to create fresh content for each web page you design. If you plan on creating two pages about winter jackets, one for children and one for adults, don’t use 90% of the same information on both pages. Create distinct and relevant information on each topic so the search engines can see the differences between the two pages and thus rank them according to their keywords.
Here are examples of content that is not considered duplicated:
Google will not throw you in their “sandbox” and de-index your website for duplicate content like most people believe.
Google themselves have said there is no penalties from duplicated content. (Read more on that here.) Well, at least not in the way most people expect. There will be no harsh repercussions from Google or other search engines should they find some duplicated text or multiples of the same webpages throughout your website. While this is a relief to some, there are things you should be concerned about. Google omits duplicate content from search results which means webpages that include duplicate content will not appear in general search engine result pages (SERPs) which could greatly hurt the traffic heading to your website.
There are ways to deal with duplicate content throughout your website and across other web domains. While it can take some serious time and work, proactively addressing these issues will ensure that users see the content that you want them to. It will also ensure that the right web pages appear in search results to increase your traffic and visits to your site. Here are some good SEO practices to follow when dealing with duplicate content:
Use “301 Redirects”
Setting up a 301 Redirect on duplicate pages will connect or link them to the main page with the original content. Essentially, this action will combine multiple pages that have the potential to rank well into a single page, thus creating a strong popularity signal to search engine spiders. The pages no longer compete with each other, but instead work together to help increase relevance.
Use Rel=”canonical”
Another great way to combat duplicate content is to add rel=canonical tag to URLs that have the same content as another web page. By adding a rel=“canonical” tag in the <head> section of any web pages that contain duplicate content, you are telling search engine spiders that it is a duplicate of the canonical URL mentioned. The search engine spider then knows which page to show in search results and where to point all the incoming link juice.
Note: You may be wondering what the major difference is between a 301 redirect and a rel+canonical tag. Plain and simple, adding a rel=“canonical” tags still keeps the page visible to users, while a 301 redirect on the other hand points both search engine spiders and users to the preferred page only. For instance, a 301 redirect should be used in instances where you have http://abc123.com and http://www.abc123.com as homepages. Choose whether the WWW or the non-WWW is more popular than add a 301 redirect to the other. The one with the 301 redirect will no longer show up in SERPs.
Use “noindex” “no follow”
Utilizing the meta robots tag “noindex” or “nofollow” will allow search engine bots to crawl the links on the web page but it will keep the spider from indexing the page in the SERPs. This technique should be implemented only on pages that you do not want indexed in search engines.
Utilize Google Webmaster Tools 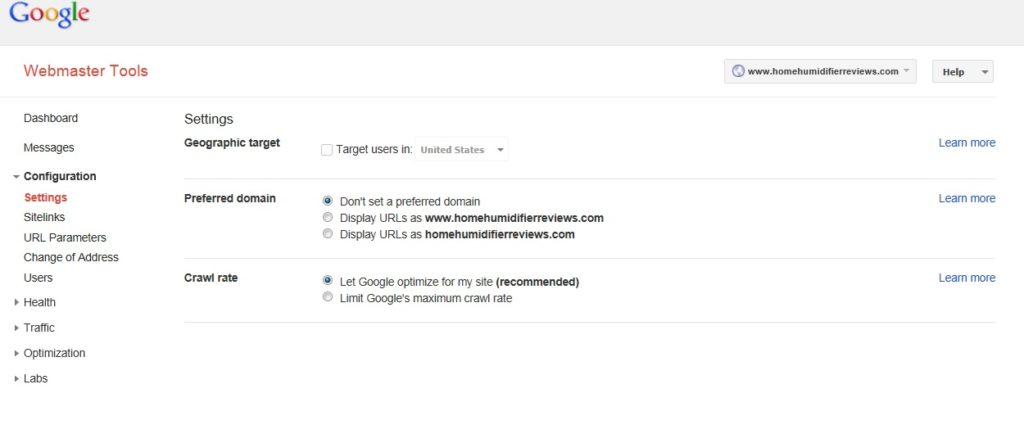
Google Webmaster Tools (GWT) is especially handy if you are not familiar with coding or building websites with HTML. In GWT you can set your preferred URLs by going to Configuration>Sitelink>Preferred Domain. Here you can choose whether you want to have your indexed URL include WWW or not. GWT also allows you to set individual URL parameters so you can instruct the search index spiders how to handle duplicate content for categories such as IDs, URLs, and Tags. (Here’s a great article on setting URL parameters.) Clicking on “HTML Improvements” will help you identify and address duplicate content issues.
While those are the top four ways to combat duplicate content, here are a few other methods to consider to help ensure your website performs appropriately:
Knowing is half the battle, and that includes issues with duplicate content. Once you know what to look for and avoid, you can take proactive steps to combatting it. Contact our SEO specialists for more information on the duplicate content battle and how we can help you.